einstein (São Paulo). 03/Feb/2026;24:eAO1436.
Performance of the Artificial Intelligence large language models ChatGPT 3.5, Gemini (Google Bard), ChatGPT 4.0, and Gemini 2.5 flash in surgical subspecialty questions of Brazilian medical residency exams
DOI: 10.31744/einstein_journal/2026AO1436
Highlights
■ ChatGPT and Gemini are showing increased ability to accurately answer multiple-choice questions on medical exams.
■ There was no statistical significance in the rate of correct answers by ChatGPT 3.5 and Gemini 1.5. However, we observed that ChatGPT 4.0 performed significantly better, and so did Gemini 2.5 Flash, when comparing to the literature.
■ The question taxonomy did not appear to be a relevant factor regarding the success rate of the models.
ABSTRACT
Objective:
Given the rapid advancement of Artificial Intelligence and its significant impact on medical education, particularly with the development of large language models, such as ChatGPT and Gemini, ChatBots have shown an increasing ability to support clinical reasoning. Regarding this, there has been a growing interest in assessing the performance of ChatBots in medical examinations. However, there are insufficient data on these tools for addressing Brazilian medical exam-related inquiries, as well as their potential as educational tools for medical students. Therefore, we aimed to evaluate the performance of Artificial Intelligence on residency entrance exams for surgical subspecialties in six different surgical residency programs.
Methods:
We analyzed the performance of ChatGPT 3.5, Gemini (Google Bard), ChatGPT 4.0, and Gemini 2.5 Flash on 464 practice questions from six major institutions in São Paulo that offer surgical medical residency programs. The questions were multiple-choice, and each had a single correct answer.
Results:
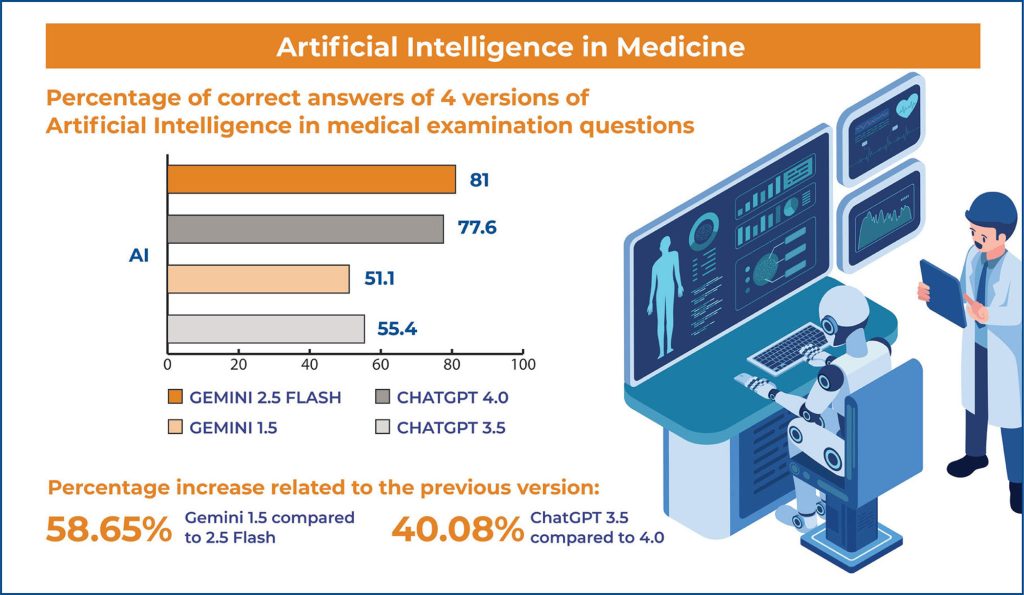
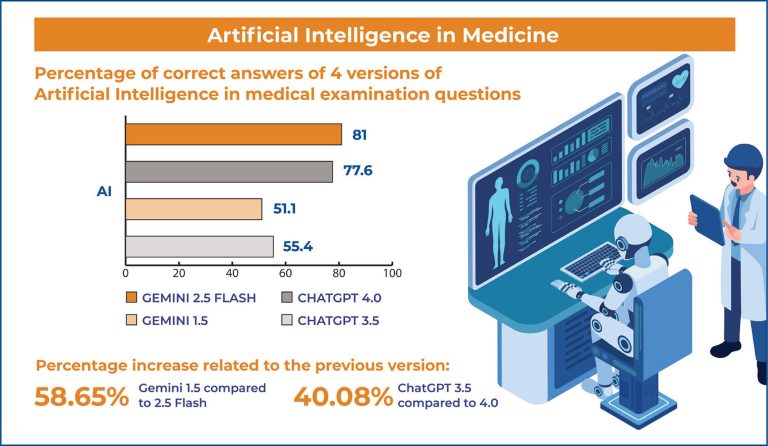
Overall, ChatGPT 3.5 correctly answered 257 (55.4%), Gemini (Bard) 237 (51.1%), ChatGPT4.0 360 (77.6%), and Gemini 2.5 Flash 376 (81%) out of 464 questions, showing a substantial increase in performance.
Conclusion:
These findings underscore the potential of advanced large language models to support medical education. Although it is unlikely that these platforms will replace the clinical decision-making skills of surgeons trained by higher education institutions, when used appropriately, they may serve as an adjunct tool for medical education.
[…]
75